To set up Continuous Profiling, navigate to the Getting Started - APM section.
Flame Graph
Flame Graphs displays the total amount of memory (in RAM) that each operation accrues in your distributed system. Each operation is an individual node and is presented in a hierarchical format. The longer the node, the more memory that operation has consumed. This view is useful for identifying common resource requests, quickly assessing performance hotspots, and filtering through specific services.Continuous Profiling Table
The Continuous Profiling Table organizes the same data presented in the Flame Graph in a column-oriented representation. Each row in the table corresponds to an individual operation, with the Self column representing the amount of memory (in RAM) used when that operation fires once, and the Total column representing all of the memory used by that parent operation. This is useful for comparing the difference between the volume of memory being used for a single service compared to the total memory usage of the parent span.Sandwich Graph
The Sandwich Graph allows you to break down your Flame Graph by parent and child functions. Parent functions are named Callers, which are the original functions in question. Child functions are named Callees, the functions that the original function in question has called. This is useful for mitigating redundancies across different function calls and reducing the total amount of memory used across your entire system.Continuous Profiling Support Matrix
The following table shows what Continuous Profiling features are available per each APM:Profiling A Flask Web Application
Although this guide focuses on a Python-specific implementation, Middleware supports all major programming languages. You can find instructions for your language of choice in our APM Documentation.
Prerequisites
1
MW Agent Installed
The MW Host Agent must already be installed
2
VPS or Cloud Computer
Access to a VPS or a cloud computer service instance like EC2, Azure VM, or Digital Ocean Droplet
Create Your Flask App
calculations.py
calculations.py
calculations.py contains a set of functions that allows us to simulate a bottleneck, along with other functions that perform some mathematical calculations:calc1 - a function with a quadratic time complexity.calc2 - a function with a quadratic time complexity. It’s a bit different from calc 1 because it does not have the extra square root added to the value. Both calc1 and calc2 simply serve to demonstrate calc3 as a bottleneck.calc3 - a function with a factorial time complexity.efficient - a function that calls calc1 and calc2 and returns a sum of those functions.with_bottlneck - a function that calls calc1 calc2 and calc3 and returns a sum of those functions. calc3 will be our bottleneck function in this example.Python
app.py
app.py
app.py contains our Flask application with two endpoints./calculate1 - an endpoint designed to be faster than calculate2 and calls calculations.efficient()/calculate2 - calls the calculations.with_bottleneck() function and is comparatively slower than the /calculate1 endpoint.Python
wsgi.py
wsgi.py
wsgi.py is a file Gunicorn will use to run our Flask app.Python
Finding a Bottleneck
After creating the application and deploying it to the platform of your choice, follow the steps from Python APM, login to middleware.io, and head to APM > Continuous Profiling. To identify individual functions/methods that consume a significant amount of CPU time, click on the Table and Flamegraph section. Within the table, sort the functions/methods by the amount of time they consume in descending order by clicking on the “Self” header.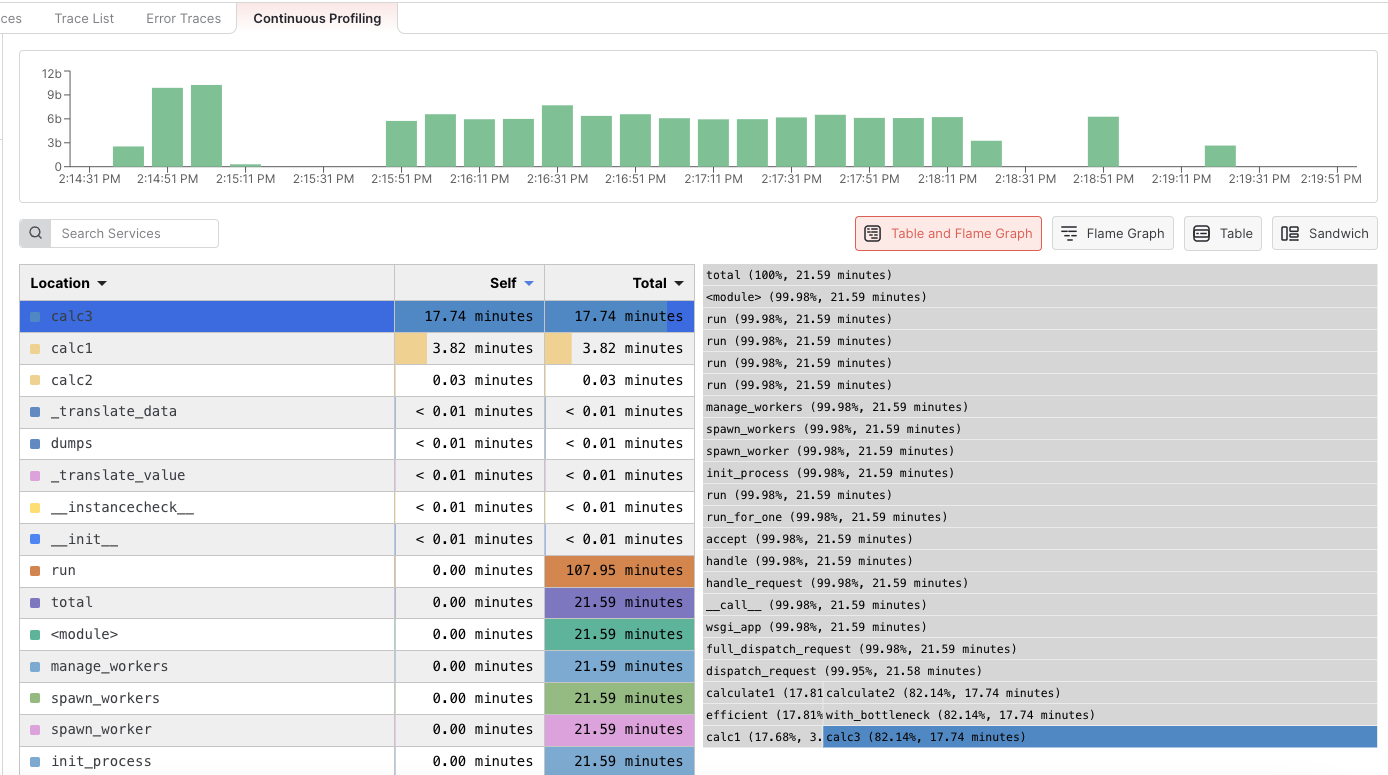 In this example, it’s clear that the
In this example, it’s clear that the calc3 function is causing a notable bottleneck in our application.
By clicking on the function name calc3 in the table, the function will also be highlighted in the flame graph. This will show the call stack with caller functions at the top and callee functions going toward the bottom.
Next Steps
Need assistance or want to learn more about Middleware? Contact us at support[at]middleware.io.